Sequencher是一款功能强大的dna序列分析软件。非常好用的dna序列分析工具Sequencher。用户可以在软件中创建新的分析计划,或使用官方实验模板在软件中创建分析项目。模板是一种特殊类型的项目,可以通过选择参数和首选项进行设置。模板可以包括普通序列或参考序列。首选项可以包括功能设置,酶设置和显示设置。使用模板,您还可以设置“装配参数”,“按名称装配”手柄和“修剪”参数来创建差异表,并且可以在相同的重叠群中设置序列的差异表,当您准备开始创建时方差表,您可以从重叠群中选择一个序列,或转到“项目窗口”,然后单击其图标以选择重叠群。这将选择重叠群的所有序列。可在软件中使用Sequencher自动定序器中的色谱图可帮助您编辑重叠群,支持显示迹线和二级峰以发现杂合子,支持编辑碱基迹线或还原为实验数据,支持显示限制性图谱,您可以使用“在窗口中选择其序列图标,然后打开编辑器以查看序列或重叠群的限制性图谱。
使用说明:
会议策略
Sequencher为您提供了执行序列组装的强大选项。在许多情况下,默认选项会表现良好。但是,实验上的差异会影响您的数据,因此有时您可能需要更改装配参数。以下是组装数据的基本策略。
•从严格的参数开始,以最大程度地减少不正确匹配的可能性。选择要组装的顺序,然后使用“自动组装”选项。自动组装依赖于详细的搜索和比较算法。
•如果某些序列未汇编,请降低参数的严格性,然后再次尝试自动汇编。
•如果所选参数变得过于宽松,以至于“自动组装”过程可能导致一条路线不受科学支持,则应切换到交互式路线,以便好地控制该过程
设定组装条件
设置装配参数
要更改参数设置,请选择项目窗口。然后在“项目”(Project)窗口中单击“装配参数”(Assembly Parameters)按钮,或转到“重叠区”(Contig)菜单并选择“装配参数”(Assembly Parameters)命令。 Sequencher将显示如下所示的对话框。
装配参数对话框
图:装配体参数对话框
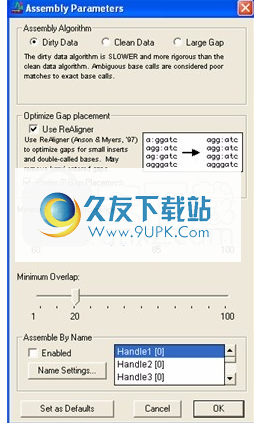
Sequencher使用在此窗口中设置的值来控制其组装序列的方式。设置选项后,您需要单击“确定”按钮以关闭“装配参数”窗口。
组装算法
要选择要使用的组装算法,请在“项目”窗口上单击“组装参数”按钮,然后单击窗口顶部的三个单选按钮之一。您的选择将取决于您的数据。
例如,如果单击“清除数据”单选按钮,重叠群将更快,但是如果序列的末尾包含很多歧义,则Sequencher可能会错过一些可能的匹配项。为了获得最佳性能,请确保已按顺序修剪了质量较差的数据。
脏数据算法较慢,因为
对于Sequencher,序列之间的执行是严格的。您应该意识到,自动定序器会创建脏数据,并且Sequencher的算法已针对此问题进行了优化。
gap大缺口算法使您可以组装预期包含大于10个碱基的插入和缺失(缺口)的序列。通常在进化研究和不同生物的序列比较中发现这种缺口。大间隙算法类似于脏数据算法,但是速度较慢,但是执行组装时允许较大间隙。需要大间隙算法的装配的典型例子包括将cDNA序列与基因组序列进行比较,以及相关基因的装配和选择性剪接。
清理脏数据
转到“装配参数”对话框,然后选择“脏数据”单选按钮。有两个滑块可用于更改最小匹配值。要设置必须匹配的碱基百分比,请使用“最小匹配百分比”滑块。要设置必须重叠的最小基数,请使用“最小重叠”滑块。
通过将光标放在滑块上,按住鼠标按钮并将滑块向左或向右拖动来更改设置。移动滑块时,设置值将自动更新。
例如,如果您尝试组装一个与所选1000个碱基序列完全匹配的17个碱基的序列,并将最小重叠设置为20个碱基(Sequencher的默认最小重叠),则这两个片段将不会进行组装。您必须首先将最小重叠减少到17个碱基或更少,然后组装片段。
整理干净的数据
清除数据”算法时,可以使用称为“最大循环输出大小”的附加选项。它具有用于调节尺寸值的升降器按钮(下图)。此参数是潜在重叠中可接受的连续不匹配碱基的最大数目。通过将光标放在滑块上,按住鼠标按钮,并上下拖动滑块来更改滑块设置。可以设置的最大值为6。
要设置必须匹配的碱基比例,请使用“最小匹配百分比”滑块。要设置必须重叠的最小基数,请使用“最小重叠”滑块。
显示最大循环输出大小的Clean Data算法
图:显示最大循环输出大小的数据清理算法

大间隙组装
大间隙算法专门用于具有或可能具有较大插入或间隙的数据。这可能包括来自进化研究,不同生物或将cDNA与基因组DNA进行比较的数据。选择大间隙算法时,有两个滑块可用于更改最小匹配值。要设置必须匹配的碱基百分比,请使用“最小匹配百分比”滑块。要设置必须重叠的最小基数,请使用“最小重叠”滑块。
注意:“装配参考”不能与大间隙算法一起使用。
完美的组装条件
最低游戏百分比
最小匹配百分比可用于所有三种组装算法。它用于设置在Sequencher接受序列实际重叠之前必须在候选序列中匹配的碱基比例。可以通过移动滑块来更改默认值85%。
如果此值不给您任何重叠,则可能需要通过将滑块向左移动以减小百分比来减小“最小匹配百分比”。
如果您有不正确或意外的重叠,则可能需要通过向右移动滑块(更高的百分比)来增加“最小匹配百分比”。
最小重叠
最小的重叠可用于所有三种组装算法。它用于设置在Sequencher接受序列作为实际重叠之前必须重叠的最小碱基数。可以通过移动滑块来更改默认值20。
如果此值不给您任何重叠,则可以通过将滑块向左移动以指示必须重叠的基数较少来减少“最小重叠”。
如果您有不正确或意外的重叠,则可能需要通过将滑块向右移动(必须重叠的碱基数量更大)来增加“最小重叠”。
最大振铃尺寸
最大回路输出大小是在潜在重叠中可接受的连续不匹配碱基的最大数量(在这种情况下,间隔也被视为不匹配)。通过向上或向下改变电梯来设置不匹配基准。可以手动设置的最大值为6。请记住,此选项只能与“清理数据”算法一起使用。
优化间隙位置
ReAligner是一个可选步骤,可与Clean Data和Dirty Data算法一起使用。它评估重叠群和操作区中的缺口分布
发他们的立场。 ReAligner有助于按共有序列进行编辑,并清楚显示插入和删除的效果。
要使用ReAligner,请选中“装配参数”对话框中的复选框。在DNA分析的某些领域,标准是收集右侧的空白。如有必要,请选择“首选3'间隙放置”。
注意:此选项不能与大间隙算法一起使用。
组装
自动组装
将项目窗口置于最前面,然后选择要组装的序列片段。单击“自动组装”按钮或进入“重叠群”菜单,选择“组装重叠群”命令,然后从子菜单中选择“自动组装”。 Sequencher比较所有选定的序列,包括反向互补,并组装落入选定装配参数内的最佳匹配。
组装完成后,将显示咨询窗口。 (请参见下图。)单击“关闭”返回到“项目窗口”。
组装完成报警
图片:组装完成警报

将选定的项目添加到其他项目-重叠群的增量构建
装配选项“将选定的项目添加到其他项目”是自动装配的一种特殊情况,当数据集不断增长时,这非常有用。 Sequencher将所有选定(新)项目与未选定(旧)项目进行比较。新项目也将进行比较。它旨在提高处理大量序列的效率,例如DNA库聚类和基因组装配。因此,它将不会再次比较任何未选择的项目。
转到“重叠群”菜单,然后单击“将选定的项目添加到其他”,然后单击“组装重叠群”。
组装参考
使用“参考组装”命令,可以将样品组装为单个参考序列,而无需考虑各个片段之间的不一致之处。因为这是多对一比较,而不是正常的多对多比较,所以“参考程序集”比标准的“自动程序集”算法快得多。
要使用此命令,您需要指定一个参考序列。单击您的序列,然后转到序列菜单,然后选择参考序列。现在,选择要组装的序列片段,包括参考序列。单击“按参考装配”按钮,或从“继续”菜单中选择“连续体”命令,然后从子菜单中选择“按参考装配”。
互动组装
每当您要完全控制一批序列的装配时,都可以使用“交互式装配”算法。 “交互式装配”窗口为您提供有关任何给定序列与一组候选序列之间的重叠,不匹配和缺口的详细信息。候选程序集由用户定义的程序集参数设置驱动。
进行互动集会
将项目窗口置于最前面,然后选择要组装的项目。单击“项目窗口”顶部的“交互式装配”按钮,或转到“重叠区”菜单,然后从子菜单中选择“装配重叠区”,然后选择“交互式...”。
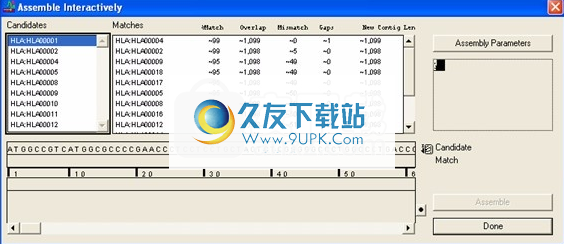
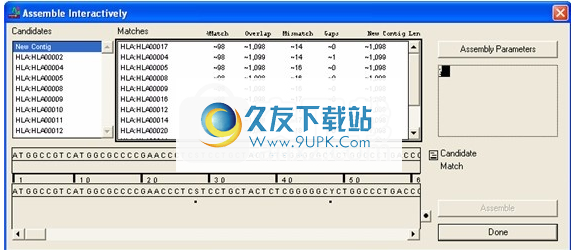
Sequencher将显示“交互式装配”对话框,如下图所示。所选的序列和重叠群显示在“候选”列表中。右面板在左上角显示一个名为“ agent”的面孔。它显示有关您要求的比较的信息。中间的“匹配”面板显示可能的匹配。对于面板中的每个匹配项,Sequencher将列出“%匹配”,“重叠碱基”的近似数量,“不匹配碱基”的数量,“间隙”的数量和“新重叠区长度”。
第一行显示候选序列,其下面的行显示匹配序列。在这两行下方是共识序列。共识右侧有一个带有黑色圆圈的小按钮。如果重复单击此按钮,则可以一次显示第一,第二,第三阅读框或所有三个阅读框。按钮上的标签将更改以反映这些选择中的哪个处于活动状态。
交互式装配对话框
图:“交互式装配”对话框

要使Sequencher将任何单个序列或重叠群与“候选”列表中的其他项目进行比较,请在“候选列表”中单击序列或重叠群的名称。比较完成后,可能的匹配出现在“候选”列表右侧的“匹配”列表中,如下图所示。
交互式程序集显示候选人及其比赛
图:显示候选人及其匹配项的交互式程序集
如果Sequencher找不到匹配项,如下所示,代理面板将显示一条消息,说明情况。
找不到匹配项
图片:没有匹配项
发现

在“匹配”列表中单击可能的匹配时,Sequencher会重新计算间隙的最佳位置。然后,代理将显示有关所选序列及其计算出的重叠的消息。
重叠的开始和基本共识出现在交互式装配框底部的字段中(下图)。您可以通过向右移动滚动条来进一步探索对齐方式。
交互式装配窗口显示重叠
图片:“交互式装配”窗口显示重叠
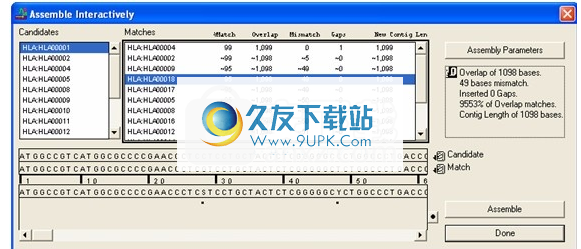
如果选择创建此装配,则单击“装配”按钮。在“设置名称”对话框窗口中为新重叠群命名,然后单击“确定”。 Sequencher可以在很短的时间内组装(或重新组装)重叠群,新重叠群的名称现在出现在“候选”列表的顶部。请注意,当序列被组合时,其名称将从“候选”列表中删除。
在“交互式装配”窗口中显示新的重叠群
图片:“交互装配”窗口中显示的新重叠群
通过单击“完成”按钮关闭“以交互方式组装”对话框时,新的重叠群将出现在“项目窗口”中。
更改交互式装配的参数
如果您怀疑片段应该形成重叠群,但Sequencher无法建议候选匹配,则可以更改装配参数。为此,在使用“交互式装配”时,单击“装配参数”按钮。将出现“装配参数”对话框。将设置更改为满意的设置后,单击“确定”返回到“交互式装配”窗口。
不经意地加入
轻松连接可让您将序列放在一起,而无需使用常规算法集。您可能希望这样做的情况的例子包括准备质粒或构建人工cDNA序列。
通过在序列周围拖动一个框或按住Shift并单击它们来选择要加入的序列。
注意:它们将按照您选择它们的顺序列出在新重叠群中。
进入“重叠群”菜单,然后选择“组合重叠群”,然后从子菜单中选择“无意加入”。如果启用了“按名称组装”,则“无缝连接”子菜单项将变为“按名称连接”。按名称连接并使用句柄适当地对序列进行分组。
然后,Sequencher会询问您是否要比对重叠群左侧(“所有左侧”),重叠群右侧(“所有右侧”)的所有序列,或者合并“端对端”。单击适当的按钮。所选项目将被组装,并由项目窗口中的contig图标代替。
按名称连接对话框
图:“按名称连接”对话框

按名称组合策略
样品名称通常包含诸如引物,模板,克隆名称或样品来源之类的信息。 Sequencher提供了一些工具来分隔序列名称的描述性部分,并使用它们来管理程序集。这些工具是程序集句柄和名称分隔符。
组装句柄是序列名称中的任何字符集,可以提供有关序列的信息,例如引物或克隆名称。名称分隔符将每个程序集句柄与下一个句柄分开。序列名称通常具有多个程序集句柄和名称分隔符。
在最简单的形式中,名称分隔符可以是短划线或下划线之类的字符。
使用名称定界符时,它将如下所示:
手柄1手柄2手柄3
要么
Handle1_handle2_handle3。
但是,名称分隔符也可以是字母,数字和字符的组合。
若要定义名称定界符,Sequencher在“按名称组装”设置对话框的下拉菜单中提供了一组常用字符。如果转到“装配参数”并单击“名称设置...”按钮,将看到此菜单。如果您的命名约定不使用简单字符作为“名称分隔符”,则可以使用称为“正则表达式”的形式化描述符,我们将在本章稍后介绍。
定义装配手柄后,即可装配项目中的所有序列。仅共享相同装配手柄的序列将被分析以适合同一重叠群。例如,在临床应用中,可以创建多个重叠群,每个重叠群仅代表单个患者的序列数据,前提是每个样本(患者)的名称具有唯一的装配句柄。
按名称条件设置装配
使用单个定界符配置程序集句柄
在“项目”窗口中,单击“装配参数”按钮。在“装配参数”窗口的底部,单击“名称设置...”按钮。下图显示了“按名称组装”窗口。
组装设置w
按名字称赞
图片:按名称组装设置窗口
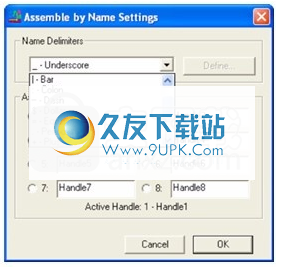
如果“程序集句柄”由“名称分隔符”下拉菜单中包含的单个字符分隔,请从列表中选择该字符。 否则,请遵循高级表达式的说明。
名称分隔符下拉菜单
图片:名称分隔符下拉菜单
什么是正则表达式
正则表达式是一种使用字母,数字和特殊字符描述文本模式的方法。这些表达遵循某些语法规则。
在“项目”窗口中,单击“装配参数”按钮。在“装配参数”窗口的底部,单击“名称设置...”按钮。出现“按名称组装设置”窗口。
从“名称分隔符”下拉菜单中选择“高级表达式...”。您会注意到,“定义...”按钮现已启用。单击定义...按钮。
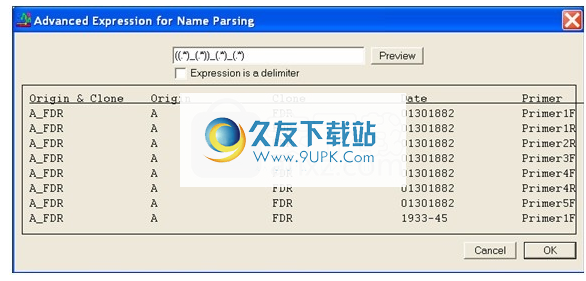
出现“名称解析高级表达式”窗口。窗口顶部是一个文本框,您可以在其中输入正则表达式。
按名称组合和使用正则表达式有两种方法。选中“表达式是分隔符”框时,键入的正则表达式允许您定义分隔符选项,而不是下拉单中可用的选项。
如果未选中“表达式是分隔符”框,则您的正则表达式必须在序列名称中完全定义每个程序集句柄和名称分隔符。除非它描述了序列的全名,否则您编写的正则表达式将不起作用。在文本字段中键入正则表达式时,它应采用以下形式:
(组装手柄1)名称分隔符(组装手柄2)
在下面的示例中,正则表达式用于组合序列名称的前两个部分Origin和Clone,以创建新的Assembly Handle Origin&Clone。预览按钮显示正则表达式的结果。如果满意,请单击“确定”按钮。
名称解析高级表达式对话框窗口
图:“用于名称解析的高级表达式”对话框窗口
设置程序集句柄名称
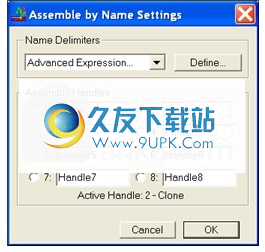
在“项目”窗口中,单击“装配参数”按钮。在“装配参数”窗口的底部,单击“名称设置...”按钮。出现“按名称组装设置”窗口,如下图所示。
您最多可以描述八个装配手柄,并且在任何时候都只有一个处于活动状态。
对于每个装配手柄,您可以使用Sequencher自动为重叠群分配的默认名称,也可以在文本框中键入描述性标题。单击要激活的手柄左侧的单选按钮。 Sequencher在此对话框的底部显示活动手柄的编号和名称。单击确定按钮退出此窗口并返到“装配参数”窗口。
“按名称组装”设置窗口
软件功能:
1.SNP检测
使用Sequencher比较比对,以鉴定和报告SNP和突变。例如,调用第二个peak ..函数来分析所有序列以发现潜在的杂合子。您可以控制定义杂合子的严格性。您可以从一个杂合子跳到下一个杂合子,只需按“基本视图”中的空格键即可。您还可以观察到共识及其参考序列的转换。协议及其参考序列之间的差异将在可导出表中列出。参考序列可确保从一个装配到下一个装配的SNP数量保持相同。
2.序列组装
Sequencher的组装算法可以快速,准确地组装您的DNA片段。实用的工具可让您在几秒钟内设置并调整参数。您可以组装顺序,而无需考虑方向。 Sequencher比较前端并反转补码方向,以组装最可能的Contig。
3.序列编辑
Sequencher可以给您足够的信心,说序列绝对正确。您只能观察一个色谱图序列,也可以同时从正面或相反方向查看多个对齐的色谱图。滚动浏览对齐的数据很容易。您可以使用Sequencher的选择工具突出显示不一致或低质量的区域。
4.自动分析
Sequencher可以批量处理您的数据。此过程是透明的,用户可定义的且可恢复的,并且Sequencher绝不会破坏出于自动化目的的科学结论的正确性。
当您按多个顺序工作时,Sequencher可以:
叫第二个高峰
调整向量
调整低质量端
建立共识序列
恢复实验数据
Sequencher始终管理数据的两个副本,一个被编辑,另一个是原始导入的数据。将“还原为实验数据”命令应用于项目中的选定序列或序列的选定部分时,可以撤消全部或部分编辑动作。
从4.5开始,Sequencher包含了一个新的自动化工具“按名称组装”。依靠“按名称组装”,您可以选择片段名称的一部分作为共享标识符或“组装句柄”。 Sequencher可以自动将选择和名称转换为Contig。例如,单击按钮,您可以将90个文件,45对前端和反向序列转换为根据患者编号命名的45个重叠群。组装参数的每一次更改都会重组您的片段,因此您可以根据克隆号,日期,引物或序列名称中记录的任何其他特征组装Contig。
5.矢量调整
自动定序器根据呼叫错误生成结果。从DNA文库克隆的序列通常包括载体序列,polyA尾巴或其他无关序列。内含子和引物序列通常侧接扩增的外显子序列。如果不进行调整,这些污染物会使您的组装和下游分析失真。 Sequencher允许您调整低质量或模糊的数据。 “修剪末端”从序列片段的末端除去误导性数据。 “修剪矢量”(Trim Vector)在受污染序列的末尾删除特定序列数据。 “修剪参考”删除超过装配参考序列的序列尾。
安装方式:
1.打开Sequencher 5.4.5.exe软件并直接安装。这里显示许多PDF文件。自己读
2.提示软件的安装向导界面,点击下一步
3.软件安装协议的内容,点击接受协议
4.提示软件准备安装在界面上,单击“安装”以执行安装
5.软件安装进度界面,等待Sequencher 5.4.5.exe安装完成
6.Sequencher已成功安装,单击“完成”以结束安装
软件特色:
关于项目窗口
该项目的概念对Sequencher非常重要。用户在项目框架内工作。一个Sequencher项目包括DNA序列和重叠序列的集合(连续序列
重叠序列的点火),这些序列是由这些序列构成的。一个项目可以是任何大小。
重叠群
DNA测序是一个容易出错的过程,因此来自自动DNA测序仪的碱基检出可能无法正确表示要测序的样品。这意味着使用自动DNA测序数据时,通常需要检查和编辑重叠群。
Sequencher在用户和数据之间提供了强大的界面,因此您可以根据自己的规范分析和编辑序列和重叠群。您可以直接从一个歧义或歧义移至下一个歧义或歧义,以分析和覆盖碱基检出错误,从而消除差异和歧义。 Sequencher允许您从许共识计算中进行选择,并在编辑序列时不断重新计算重叠群的共识。
编辑重叠群
我们解释了如何找到歧义和低置信度需要注意的基础。我们讨论了如何执行编辑,移动和删除碱基和序列,插入缺口或碱基以及基于共有序列创建新序列。您将学习如何比较序列以突出显示差异以及如何创建自定义报告。
找到关注的基础
您的数据显示中可能会看到许多问题。有些将需要检查,也许需要编辑。这些问题可能表示为N,意见分歧,差距或信心不足。您可以使用重叠群的共识序列中“选择”菜单中的“下一步”命令来查找任何这些问题区域。
一旦使用了任何Next命令,Sequencher将激活空格键以执行操作。如果您连续两次使用菜单命令或快捷键组合,Sequencher会提醒您该更简单的替代方法可用。
方差表
方差表以最简单的形式比较并显示两个序列之间的差异。差异表中的数据动态链接到基本重叠群中的数据。
您可以将重叠群中的一些或所有序列与重叠群的共有序列,参考序列或最上层序列进行比较。这将生成一个方差表,该表将显示样品系列与所选系列之间的差异。结果可能仅来自一个重叠群,但它可以表示数百个甚至数千个序列的集合。如果要执行从头测序,克隆检查或重新测序之类的活动,则可能要使用这种形式的方差表。
翻译差异表
如果您有兴趣注意氨基酸水平上序列或重叠群之间的差异,则应使用翻译变异表。该表与变异表之间的区别在于,它还显示密码子及其相关的氨基酸残基。翻译差异表中的每一行总结了相对于实施例在给定氨基酸位置上所有选定序列的翻译之间的差异。
您还可以创建翻译后差异表,该表汇总了项目中所选重叠群共有序列的翻译与一般参考序列的翻译之间的差异(翻译一致性差异表)。当您处理来自多个来源的多个样本并且已将“按名称组装”与参考序列一起使用时,应使用这种形式的“翻译差异表”。
从序列编辑器查看色谱图
Sequencher的色谱图显示与其他编辑器紧密集成。您可以通过打开序列的序列编辑器来查看序列片段的整个原始轨道。单击按钮栏中的“显示色谱图”按钮,或转到“窗口”菜单,然后选择“色谱图”。您可以垂直滚动(默认)或水平滚动。要更改方向,请单击片段色谱图窗口左下角的相应按钮。
Sequencher contig编辑器使您可以同时查看与通用碱基调用有关的所有色谱图数据。如果您位于重叠群的5'末端,Sequencher将在共有序列中选择最5'的碱基,并显示所有相关迹线。如果您在重叠群中的其他位置,Sequencher将在重叠群显示中选择最中央的共识库,并显示关联的轨迹。这使您可以结合其碱基检出检查任何峰的信号强度,并相应地编辑数据。
破解方法:
1.打开AMPED文件夹,然后打开Sequencher-RLMServer。将许可服务SequencherServer.exe安装到计算机上
2.提示已安装SequencherServer
3.输入安装许可证服务的地址C:\ Program Files(x86)\ Gene Codes \ Sequencher Server,然后以管理员身份启动Stop RLM Server.bat以停止当前服务。

4.将rlm.exe,genecodes.exe和genecodes.lic从AMPED目录复制到Sequencher Server目录,然后单击“替换”。
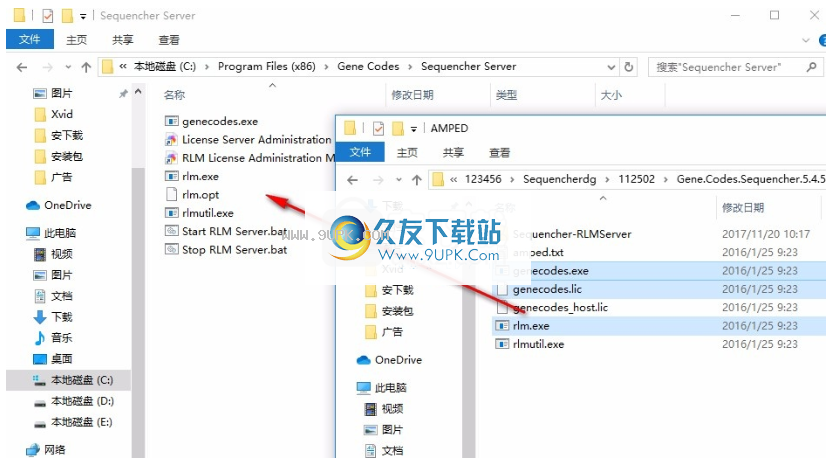
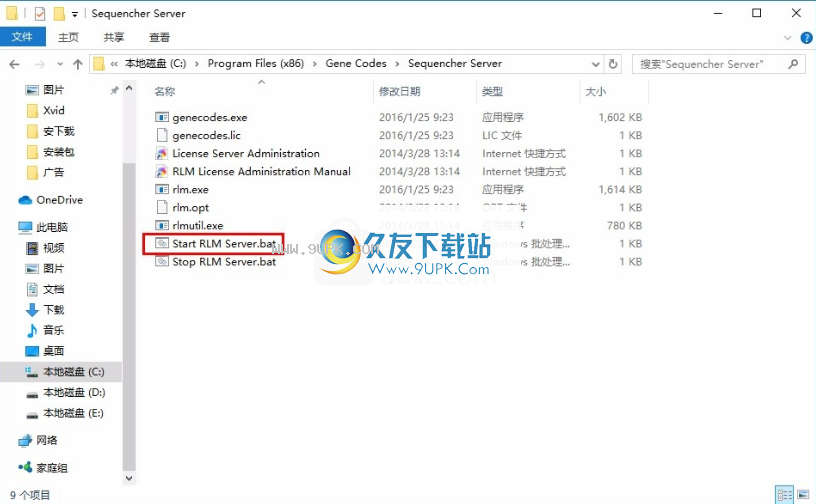
5.以管理员身份单击“启动RLM Server.bat”以启动许可服务。
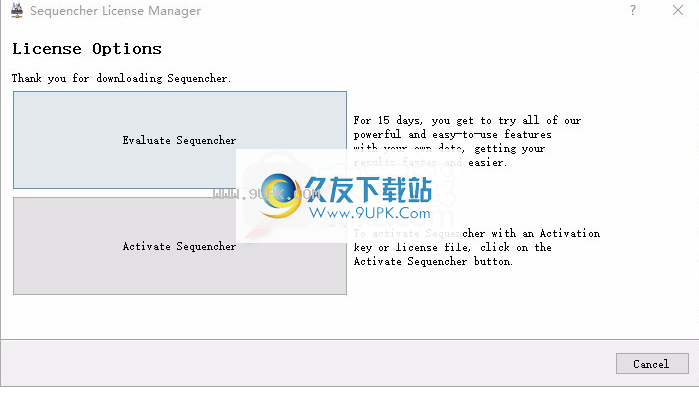
6.安装结束后打开Sequencher软件,然后单击``激活Sequencher''以激活该软件
7.单击“安装”以安装许可证功能
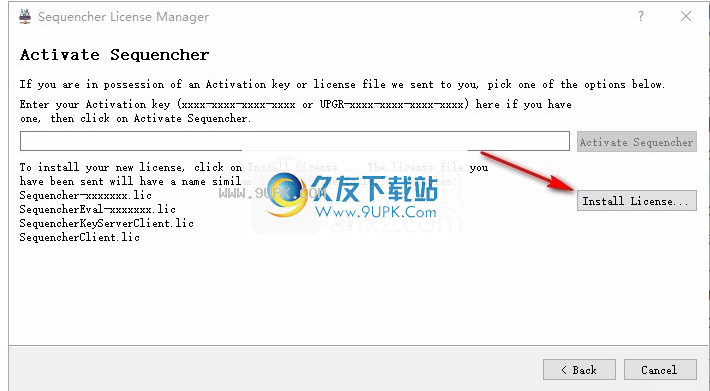
8.打开genecodes.lic,然后单击“安装”进行安装
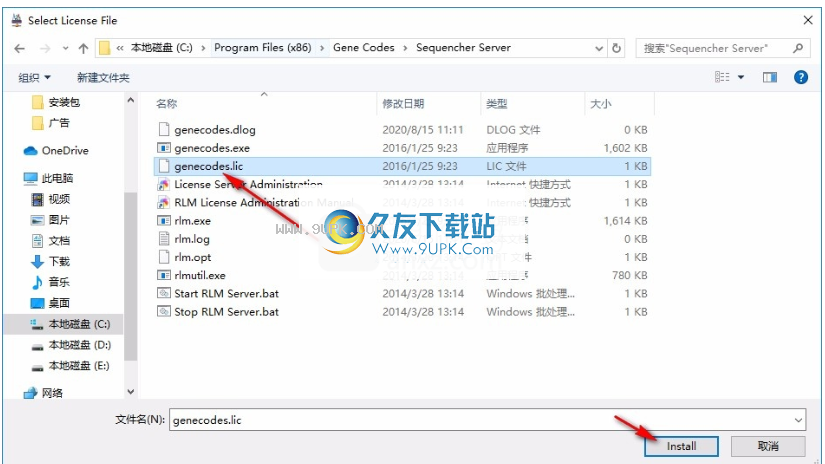
9.安装许可证后,它会提示“感谢您购买Sequencher”,“感谢您购买Sequencher”
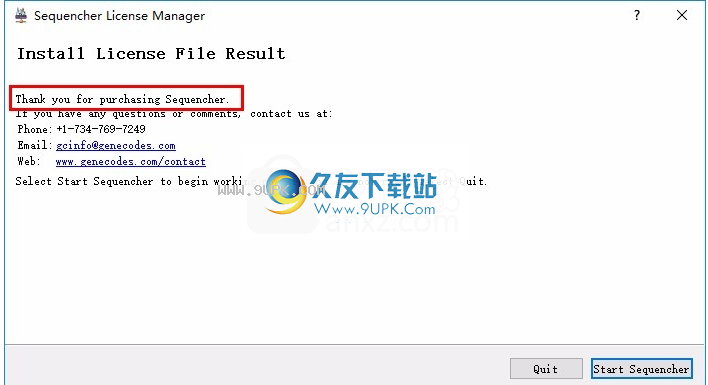
10.单击右下角的开始按钮以启动主程序

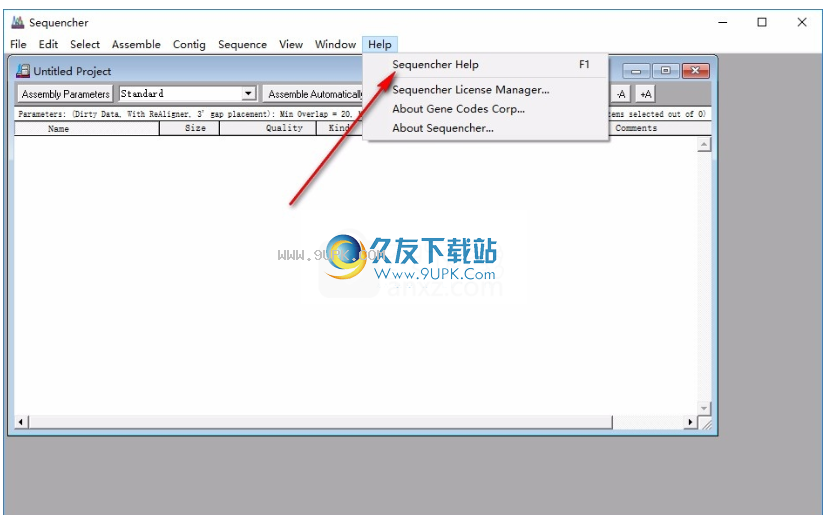
11.该软件为英文,如果您知道如何使用Sequencher,可以开始工作,可以查看Sequencher的帮助内容






















![多页面记事本[记事本软件工具] v20.15.11 免安装版](http://pic.9upk.com/soft/UploadPic/2015-11/2015112816384048708.gif)

