
MindSpore是一款专业的深度学习框架。超好用的深度学习框架MindSpore。您可以使用此软件来帮助用户在计算机上开发新的数据分析系统,以帮助各个行业提供算法分析,从而使用户在处理数据时可以获得更好的体验,并且该软件可以直接部署并用于分析。情感,可以用来分析图像,可以分析科学数据,可以分析工程数据,结合官方功能,可以在软件上建立数据集分析程序,并在功能图像上显示分析的数据,以及其他统计信息也可使用该图显示分析结果。将要分析的数据集加载到软件中以设置分析规则,支持网格的定义,支持用于推理或迁移学习的加载模型,支持将数据集转换为MindRecord,支持数据处理的优化,如果您需要此下载软件!
官方教程:
使用可视化组件MindInsight>收集摘要数据
概观
训练过程中的标量,图像,计算图和模型超参数记录在文件中,以供用户通过可视界面查看。
运营流程
准备训练脚本,并在训练脚本中指定标量,图像,计算图,模型超级参数和其他信息以记录在摘要日志文件中,然后运行训练脚本。
启动MindInsight,然后通过启动参数指定摘要目录文件目录。启动成功后,根据IP和端口访问可视化界面,访问地址为http://127.0.0.1:8080。
在培训过程中,如果写入了数据,则可以在页面上查看可见的数据。
准备训练脚本
目前,MindSpore支持将标量,图像,计算图,模型超参数和其他信息保存到摘要日志文件,并通过可视界面显示它们。
MindSpore当前支持多种将数据记录到摘要日志文件中的方法。
方法1:通过SummaryCollector自动收集
在MindSpore中,回调机制提供了支持,可快速轻松地收集一些常用信息,包括计算图,损失值,学习率,参数权重以及其他称为SummaryCollector的信息。
编写培训脚本时,只需实例化SummaryCollector,它将被应用到model.train或model.eval以自动收集一些公共信息。有关SummaryCollector英语谚语的详细用法,请参阅API文档中的mindspore.train.callback.SummaryCollector。
示例代码如下:



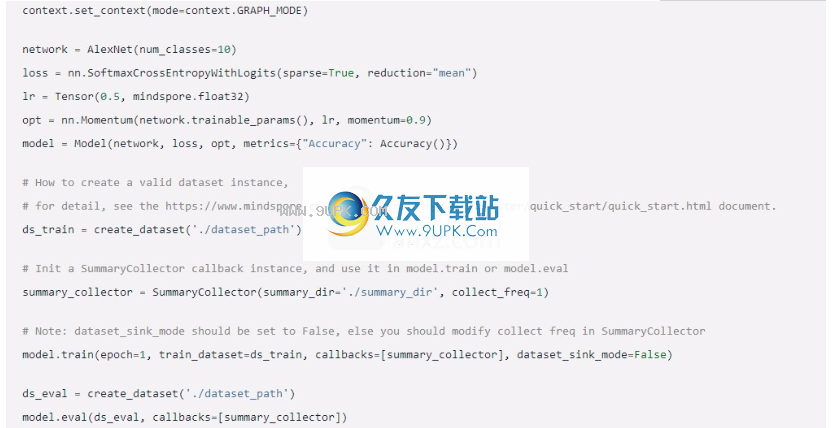
描述
使用摘要功能时,建议将model.train()的dataset_sink_mode参数设置为False。请参考文章末尾的注释。
方法2:结合使用Summary运算符和SummaryCollector来自定义网络中收集的数据
MindSpore不仅提供SummaryCollector来自动收集一些通用数据,还提供了Summary运算符,该运算符支持网络中其数据的自定义收集,例如每个卷积层的输入或损失函数中的损失值。
当前支持的摘要运算符:
标量摘要:记录标量数据
TensorSummary:记录张量数据
ImageSummary:记录图像数据
直方图摘要:将张量数据转换为直方图数据记录
录制方法如下所示。
步骤1:在继承类nn.Cell的派生类的构造函数中调用Summary运算符,以收集图像或标量数据或其他da
ta。
例如,在定义网络时,将图像数据记录在网络的结构中;在定义损失函数时,将损失值记录在损失函数的构造中。
如果要记录动态学习率,则可以在定义优化器时在优化器的构造中记录学习率。
示例代码如下:

描述
在同一汇总算法中,不能重复设置为数据设置的名称,否则数据收集和显示将具有意外行为。例如,使用两个ScalarSummary运算符来收集标量数据,并且为这两个标量设置的名称不能相同。
步骤2:在训练脚本中,实例化SummaryCollector并将其添加到model.train。
示例代码如下:
方法3:自定义回调记录数据
MindSpore支持自定义回调,并允许将数据记录在自定义回调的摘要日志文件中,并通过可视化页面进行查看。
以下伪代码显示在CNN网络上。开发人员可以使用带有原始标签和预测标签的网络输出来生成图片的重叠矩阵,然后通过SummaryRecord模块将其记录到摘要日志文件中。有关SummaryRecord的详细用法,请参阅API文档中的mindspore.train.summary.SummaryRecord。
示例代码如下:


除此之外,MindSpore还支持在训练的其他阶段保存计算图。通过将训练脚本中的context.set_context的save_graphs选项设为True,可以记录其他阶段的计算图,包括运算符融合后的计算图。
在保存的文件中,ms_output_after_hwopt.pb是运算符融合之后的计算图,可以在可视化页面上查看。
方法4:高级用法,自定义培训周期
如果您在训练期间不使用MindSpore的模型界面,请模仿模型的训练界面以自由控制循环的迭代次数。您可以模拟SummaryCollector,并使用以下方法记录摘要运算符数据。
下面的示例将演示如何使用摘要运算符和SummaryRecord的add_value接口在自定义训练循环中记录数据


使用技巧:除了上述用于记录梯度信息的使用方法外,还有一种在使用抽象数学运算符时记录梯度信息的技术。请注意,此技术需要与上述方法之一同时使用。
通过继承最佳优化器类,可以插入summary运算符以读取渐变信息。示例代码段如下:

根据上述教程,运行MindInsight以完成数据收集,然后启动MindInsight以查看收集的数据。启动MindInsight时,您需要通过--summary-base-dir参数指定摘要日志文件目录。
指定的摘要日志文件目录可以是一个培训的输出目录,也可以是多个培训输出目录的父目录。
培训的输出目录结构如下:

启动命令:

多种训练的输出目录结构如下:

启动命令:

成功启动后,通过浏览器访问http://127.0.0.1:8080地址以查看可视化页面。
停止MindInsight命令:

预防措施
1.为了控制列出摘要文件目录所花费的时间,MindInsight支持发现多达999个摘要文件目录。
2.不能同时使用多个SummaryRecord实例(SummaryRecord在SummaryCollector中使用)。
如果在mdel.train或model.eval中
如果在回调列表中使用两个或多个SummaryCollector实例,则认为同时使用SummaryRecord可能会导致数据记录失败。
如果在自定义回调中使用SummaryRecord,则不能与SummaryCollector同时使用。
正确的代码:

3.在每个摘要文件目录中,应该只有一个训练数据。如果将多个训练摘要数据放置在一个摘要摘要目录中,则MindInsight将这些训练摘要数据重叠以在可视化数据时叠加显示,这可能与预期的可视化效果不匹配。
4.当前的SummaryCollector和SummaryRecord不支持在多个GPU卡上运行的场景。
5.使用摘要功能时,请将推荐的model.train()方法的dataset_sink_mode参数设置为False,以便将该步骤用作collect_freq参数的单位来收集数据。当dataset_sink_mode为True时,将以epoch作为collect_freq的单位。建议此时手动设置collect_freq参数。 collect_freq参数的默认值为10。
6.每个步骤中保存的最大数据量限制为2147483647字节。如果超出限制,则无法记录该步骤的数据,并且会发生错误。
7.在PyNative模式下,可以正常使用SummaryCollector,但它不支持记录计算图,也不支持使用Summary运算符。
软件特色:
1.培训看板
训练看板是MindInsight可视化组件的重要组成部分,训练看板标签包括:标量可视化,参数分布图可视化,计算图可视化,数据图可视化,图像可视化和张量可视化等。
标量可视化标量可视化用于显示训练过程中标量变化的趋势。
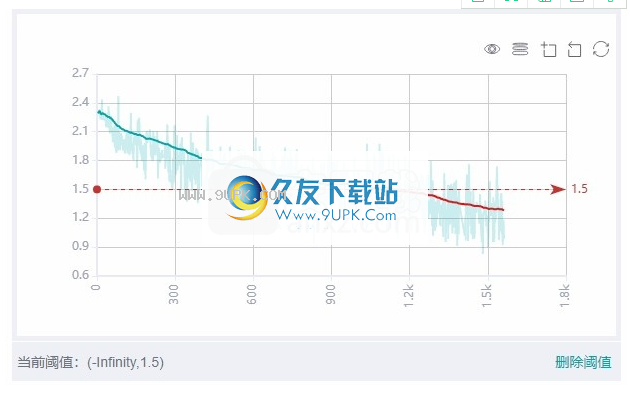
2.查看可追溯性并比较看板
MindInsight中的模型可追溯性,数据可追溯性和比较看板与培训看板属于可视化组件的同一重要部分。在训练数据的可视化中,通过比较看板以观察不同的标量趋势图来发现问题,然后使用可追溯性功能定位问题的根源,从而为用户提供有效地调整数据增强和增强功能的能力。深度神经网络。
用户通过比较分析输入可追溯性并对比看板。
模型参数选择区域,列出了可供查看的模型参数标签。用户可以通过检查所需的标签来检查相应的模型参数。
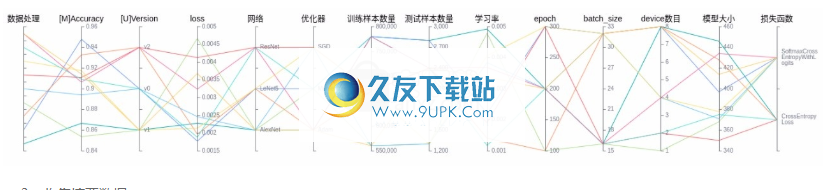
3.收集摘要数据
训练过程中的标量,图像,计算图和模型超参数记录在文件中,以供用户通过可视界面查看。
4.使用mindoptimizer进行超参数调整
MindInsight调整功能可用于搜索超参数。根据用户提供的调整配置信息,它可以自动搜索参数并执行模型训练。
MindInsight提供的mindoptimizer调整命令可以根据用户配置从训练日志中提取过去的训练记录,然后分析过去的训练记录,推荐超级参数,并最终自动执行训练脚本
5.性能调试(GPU)
培训过程中操作员耗时的信息记录在文件中,用户可以通过可视界面查看和分析该信息,从而帮助用户更有效地调试神经网络性能。
6.使用调试器
MindSpore调试器是为图模式训练提供的调试工具,可用于查看和分析计算图节点的中间结果。
在MindSpore图模式的训练过程中,用户无法从Python层获得计算图的中间节点的结果,从而使训练和调试变得困难。使用MindSpore调试器,用户可以:
在MindInsight调试器界面上组合计算图以查看图节点的输出结果;
设置监视点,监视训练异常(例如检查张量溢出),并在发生异常时跟踪错误原因;
查看参数的变化,例如权重。
7.解释模型
当前的深度学习模型主要是黑盒模型,具有良好的性能,但可解释性差。模型解释模块旨在为用户提供模型决策依据的解释,帮助用户更好地理解模型,信任模型并在模型中发生错误时有针对性地提高模型的效果。
在一些影响至关重要的应用场景中,例如自动驾驶,财务决策等,由于法律和政策监管的原因,如果无法解释AI模型,就无法真正应用它。因此,模型的可解释性变得越来越重要,受到了越来越多的关注。因此,模型解释是提高MindSpore的生态适用性和用户友好性的关键部分。
软件功能:
使用MindSpore的优势
简单的开发经验
帮助开发商取得收益
由于实现了自动网络分段,并行训练只能通过串行表达来实现,降低了门限,简化了开发过程。

灵活的调试模式
借助培训过程的静态执行和动态调试功能,开发人员可以通过更改代码行来切换模式,并快速在线查找问题。

充分发挥硬件的潜力
与Ascend处理器的最佳匹配,最大程度地提高了硬件功能,帮助开发人员缩短培训时间并提高推理性能。

在所有情况下均可快速部署
支持在云,边缘和移动电话上的快速部署,以实现更好的资源利用和隐私保护,使开发人员可以专注于创建AI应用程序。

一般场景教程
为各种情况下的不同级别的开发人员提供教程,并指导如何通过细分步骤使用MindSpore
快速开始
通过一个实例来实现手写数字识别,并使每个人都能体验MindSpore的基本功能。一般来说,完成整个样本练习需要20到30分钟。

图像分类
结合CIFAR-10数据集,说明MindSpore如何处理图像分类任务。

情绪分析
构建自然语言处理模型,通过文本分析和推理实现情感分析,完成文本的情感分类。

认识猫狗APP
在PC上重新训练预训练的模型,在移动终端上完成推理和部署,并在1小时内体验MindSpore端云全场景开发过程。



















![Ladder Master 1.74.7免安装版[丰炜plc编程器]](http://pic.9upk.com/soft/UploadPic/2014-6/201462314191395456.gif)

![DesyEdit 3.5汉化免安装版[源码文本编辑程序]](http://pic.9upk.com/soft/UploadPic/2013-6/20136147232569548.gif)
![yodas Protector 1.02汉化版[脱壳工具]](http://pic.9upk.com/soft/UploadPic/2012-5/20125301143652921.gif)


