Apache Lucene是一款强大的全文检索工具。Apache Lucene专门用于全文检索非常好用。如果需要构建搜索类型,可以选择此工具来编辑应用程序的搜索和索引方案,以附加全文搜索功能,以及软件支持文本分析,将文本转换为可图/可搜索的令牌API和代码,支持解析多个文件,可以支持多种格式,包括HTML,XML,PDF,Word,可以识别句子的开头和结尾提供更准确的短语和邻近搜索,允许用户在文本中查找您输入搜索搜索的文本,添加一个新的模块分析/ OpenNLP,其中分析器可以执行标记,单词标记,短语和短语块,并通过调用相应的OpenNLP工具来提供命名实体标识请求。处理器,如果您需要Apache Lucene下载它!
使用说明:
要使用Lucene,应用程序应该:
1,文档通过添加创建字段;
2,创建一个,indexwriter并使用文档adddocument();
3,调用queryparser.parse()来从字符串构建查询;
4.创建索引静脉,并将查询传递给其搜索()方法。
一些简单的代码示例如下:
indexfiles.java为目录中包含的所有文件创建索引。
searchfile.java提示查询并搜索索引。

Apache Lucene是一个高性能,全功能的文本搜索引擎库。这是一个简单的例子,解释了如何使用Lucene索引和搜索(使用JUnit以符合我们的期望的方式检查结果):
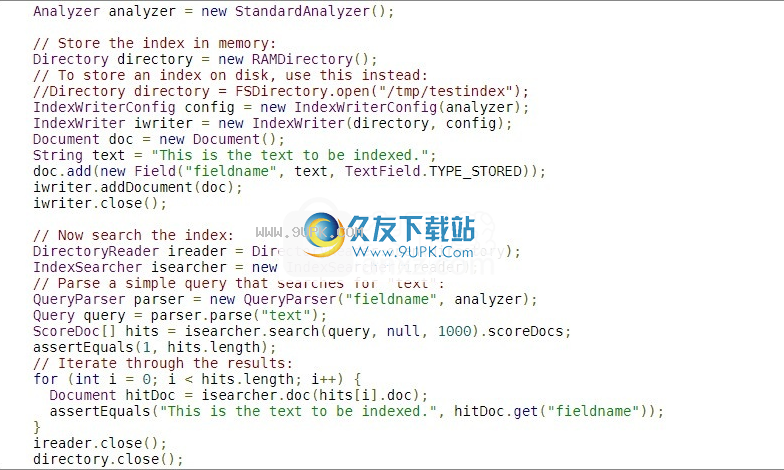
下面描述如何从基础信息检索模型实现朗涅比比(有效)。我们首先简要介绍了VSM评分,然后源自Lucene的概念评论,最后开发了Lucene的实际得分功能(后者与Lucene类和方法直接相关)。
Lucene将信息检索的布尔模型(BM)与VSM分数相结合的信息检索-BM“批准”文档。
在VSM中,文档和查询表示为多维空间中的加权向量,其中每个不同的索引项是维度,而权重是TF-IDF值。
VSM不需要将权重设置为TF-IDF值,但据信TF-IDF值可以产生高质量的搜索结果,因此Lucene使用TF-IDF。下面更详细地描述了TF和IDF,但现在已完成,我们只能为给定的时段和文件(或查询)x,tf(t,x)和项目x的窗口数(当增加,另一个增加)和IDF(t)类似地随着包含项目T的索引文件的计数而变化。
VSM评分文档D查询Q是余弦相似性加权矢量查询的代码
到v(d):

其中V(q)·v(d)是加权矢量,| v(q)|和| v(d)|是他们的欧洲里程。
注意:从某种意义上,V(Q)缩回到单位向量中,其简单的范围,上述公式可以被视为加权载体的归一化点。
Lucene改善了VSM分数,以提高搜索质量和可用性:
众所周知,v(d)对单位向量有问题,因为它删除了所有文档长度信息。对于某些文档,可以删除此信息,例如,通过复制文档,文档被复制10次,尤其是在段落由不同术语组成的情况下。但对于不包含重复段落的文件,这可能是错误的。为避免此问题,使用不同的文档长度归一化因子,其标准化为等于或大于单位:DOC-LEN-NORM(D)。
建立索引时,用户可以通过分配文档来指定与其他文档更重要的一些文档。为此,必须将每个文档的分数乘以其提升值DOC-Boost(D)。
Lucene基于该字段,因此每个查询都适用于单个字段,文档的长度取决于特定字段的长度,并且除文档之外,还有一个文档现场升级。
您可以在索引期间多次向文档添加相同的字段,因此该字段的推广是在文档中添加(或部分)的该字段的乘积。
在搜索时,用户可以指定每个查询,子查询和每个查询术语的改进,因此,查询字对文档分数的贡献乘以此查询字来贡献查询 - 升压(Q) 。
文档可以匹配准备而不是查询的所有单词(对某些查询是正确的)。
在索引中简化单个字段的假设下,我们得到了Lucene的概念评论:

从以下角度来看,概念公式是简化的:(1)列出术语和文档,(2)升级通常是针对每个查询项而不是每个查询。
现在,我们描述了Lucene如何实现这一概念评估,并借鉴了Lucene的实用得分功能。
为了进行有效的分数计算,预先计算和总结一些分数组件:
搜索开始时,您将知道查询的查询提升(实际上每个查询术语)。
查询欧洲英里规范| v(q)|您可以在搜索开始时计算,因为它与要评分的文档无关。从搜索优化的角度来看,为什么我应该为查询获得有效的问题,因为所有忽略的文档都将乘以| v(q)|。因此,文件排名(按得分排序)不会受到此标准化的影响。保持这种标准化有两个好理由:
回想一下,您可以使用余弦相似度来查找两个文档的相似性。它可用于计算使用Lucene的其他文档的相似性,例如群集,并将文档用作查询。在这种情况下,分数D3查询D1是与得分文档相当的D3查询D2。换句话说,两个不同查询的文档得分应该是可比的。其他应用程序可能需要这样做。这是两个或多个查询的比较(Q)。比较(在一定程度上)。
在准备索引时,已知的文档长度指定Doc-Len-Norm(D)和文档增强型Doc-Boost(D)。它们是预先计算的,其产品被保存为Index Norm(D)的单个值。 (在以下等式中,规范(D IN D)表示规范(DOC D中的字段D),其中字段(t)是与项目T.)相关的字段
Lucene的实际得分功能源自上面。颜色代码说明了与概念公式的关系:

如图1所示,TF(DI中的TF(T)与术语的频率相关联,定义为术语T在当前分数的文档D中出现的次数。给定的语言有更多的文件来实现更高的分数。注意假设tf(t in q)为1,因此它不会出现在此方程式中。但是,如果查询包含相同的项目两次,则存在两个项目查询相同的项目,因此计算仍然是正确的(虽然不是很有效)。默认计算TF(D IN D)IN是CLASSICIENINERY:

如图2所示,IDF(t)代表反应的频率。此值与DOCFREQ的倒计时(T出现在文档的数量)有关。这意味着术语较少的术语对总点具有很高的贡献。 IDF(t)显示在查询和文档中,如公式中的Square。 IDF(T)IN的默认计算是ClassicSiceImilarity:

3,T. GetBoost()是查询文本中查询QQ中的项目T的搜索时间增加(请参阅查询语法),或将其设置为包裹。请注意,实际上没有直接API在准备查询中访问Word增强单词,但是多个单词在查询中表示为多个对象,因此您可以通过调用子来访问查询中的单词的喜爱。 -询问。 boostquerytermquertigetboost()
如图4所示,常态(t,d)是索引时升降因子,只依赖于该字段中的标签数,因此更短的字段具有更大
API内容:
1,org.apache.lucene:顶级包装。
2,g.apache.lucene.Analysis:文本分析。
3,org.apache.lucene.Analysis.Standard:快速,通用语法令牌生成器根据Unicode标准附件#29中指定的标准说明程序,通过Unicode文本分段算法实现单词规则。
4,org.apache.lucene.alysis.Token属性:文本分析的常规属性。
5,org.apache.lucene.codecs:Codec API:用于自定义索引编码和结构的API。
6,org.apache.lucene.codecs.blocktree:blocktree术语词典。
7,org.apache.lucene.codecs.com按:SenseDifeSformat,它允许存储的字段压缩交叉文档和跨场压缩。
8,org.apache.lucene.Codecs.lucene50:lucene 5.0索引格式的索引格式组件配置org.apache.lucene.codecs.lucene 50,查看。
9,org.apache.lucene.Codecs.Lucene60:Lucene 6.0索引格式组件。
10,org.apache.lucene.codecs.lucene62:lucene 6.2索引格式组件组件关于org.apache.lucene.codecs.lucene70概述当前索引格式,请参阅。
11,org.apache.lucene.codecs.lucene70:lucene 7.0文件格式。
12,org.apache.lucene.codecs.perfield:您可以委派每个字段以获取不同格式的帖格格式。
13,org.apache.lucene.document:文档用于索引并搜索逻辑表示。
14,org.apache.lucene.geo:Lucene核心地理空间实用程序实现
15,org.apache.lucene.index:维护和访问代码。
16,org.apache.lucene.search:代码是搜索索引。
17,org.apache.lucene.search.similare:此包包含可用于Lucene的各种排名模型。
18,org.apache.lucene.search.spans:跨度计算。
19,org.apache.lucene.store:所有索引数据的二进制I / O API。
20,org.apache.lucene.util:一些实用课程。
21,org.apache.lucene.util.automaton:用于正则表达式的有限状态自动机。
22,org.apache.lucene.util.bkd:块KD树,实现这里描述的一般空间数据结构。
23,org.apache.lucene.util.fst:有限状态传感器
24,org.apache.lucene.util.graph:用于使用将用作图形的实用程序类。
25,org.apache.lucene.util.mutable:比较对象包
26,org.apache.lucene.util.packed:压缩整数阵列和流。
软件功能:
Lucene通过简单的API提供强大的功能:
1,可扩展的高性能指数
现代硬件超过每小时150GB
较小的RAM需求 - 只有1MB的桩
增量索引与批处理索引一样快
索引大小约为索引文本大小的20-30%。
2,强大,准确,高效的搜索算法
排名搜索 - 首先返回最佳结果
许多强大的查询类型:短语查询,通配符查询,邻近查询,范围查询等。
站点搜索(例如标题,作者,内容)
按任何字段排序
多索引搜索合并结果
允许同时更新和搜索
灵活的脸部,突出显示,加入和结果组
具有快速,高效存储和耐堵塞词的建议者
可插拔排名模型,包括矢量空间模型和okapi bm25
可配置存储引擎(编解码器)
3,跨平台解决方案
作为Apache许可证的开源软件允许您在业务计划中使用Lucene和开源程序
100%纯java
其他编程语言的实现兼容
软件特色:
Apache Lucenetm项目开发了一个开源搜索软件。该项目发布了一个名为Lucenetm核心的核心搜索库,以及Lucene的Python结合亚甲酰腺。
Lucene核心是一个Java库,提供强大的索引和搜索功能,以及拼写检查,命中突出显示和高级分析/令牌。塔Cynene子项目提供Python绑定Lucene的核心。
Lucene PMC非常乐意宣布Apache Lucene 8.8.2的释放。
Apache Lucene是一款高性能,装备的专业文本搜索引擎库,编写在Java中。它是几乎所有需要全文的应用程序,尤其是跨平台应用程序的应用程序。
Lucene 8.8.2分:
Lucene-9870:修复Circle2D交叉线T值(距离)范围
Lucene-9744:最小查询的NPE在最小值中查询中的最小查询$最少ummumpEsiterator.getSubMatches()。
lucene-9762:doublevaluessource.fromQuery(也用于CommanseCoreQuery.BoostByQuery)时查询需要进行评分Twophaseitor






















![A-PDF Page Crop 4.7.1免安装版[PDF页面编辑软件]](http://pic.9upk.com/soft/UploadPic/2014-8/20148271051653100.gif)