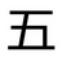
精卫输入法是一款简单易用的中文汉字输入工具。精卫输入法采用汉字的拼音、字型、偏旁三种数据进行编码而成,易于用户快速记忆,输入速度也极快,适用于高程度的汉字输入用户使用。
介绍:
精卫输入法针对中文简体字,采用四码方案,共制定十条规则,每学会一条规则就能打出百分之十的汉字。
A:声母。
A1:本输入法将汉字分为“左右型”、“上下型”、“混合型”三种字型,采用取大优先、保持拆字完整性优先的原则。除非与“D”现象冲突。
先取整字声母的头一字母为第一码,再采用拆字法原理,将各种字型中相对独立、不连不交的成字声母从左至右、从上至下、从外到内先后提出构成本字的二 码、三码、四码 。
以“新”、“星 ”、 “闻”、“旧”、“粥”、“婴”、“及”、“带”、“韩”字为例,编码分别为:
“xqj”(新亲斤)、“xrs(星日生)”、“wme(闻门耳)”、“jr”(旧日) 、“zgmg(粥弓米弓)” 、“ynbb(婴女贝贝)”、“jr”(及人)、“dj”(带巾)、“hw”(韩韦) 。
在结构中若非独立成字则不取。如“伤”字中的“力”(结构中不独立。) 、“澡”字中的“品”与“木”(结构中不独立。)、“韩”字左边的“十”与“早”(结构中相连相交。)。
全独立分离成字大部位优先的方式再按顺序取码。如“婴”、“懋”二字。全码可编为“ynbb(婴女贝贝)”、“mxmy(懋心木予)”。
以“两”、“网”、“生”、“衰”、“王”、“般”六字为例,编码分别为:
“lbr(两丙人)”、“wgy(网冈乂)”、“sny(生牛一)”、“say(衰哀一)”、“wyt(王一土)”、“bzs(般舟殳)”。【保持拆字完整性和最大化优先。】
注:“一”字除非独立成字或与其它成字、偏旁组成相对独立的字体,通常在混杂结构的字中不当成字取声编码,视为汉字的基础笔画“横”。如“长”、“豕”、“女”、“十”、“丁” 中的“一”。
B:字型。
B1:本编码分别以“U”、“i”、“V”三字母代表汉字中的“左右型”、“上下型”、“混合型(含独体字、混杂字、包围字,半包围字。)”三种字型,附在成字后面使用。
以“新”、“星”、“闻”、“旧”、“及”、“贯”、“韩”字为例,编码可分别为:“xqju”、“xrsi”、“wmev”、“jru”、“jrv”、“gbi”、“hwu”。
注:若一字不足四码并不在当前候选框内,可以继续补字型识别码。如“旧”、“及”、“贯”、三字,全码可为:“jruu”、“jrvv”、“gbii”。
C:偏旁。
C1: 本编码将汉字中常用的编旁以较通用的方式给他们下取定义,附在字型识别码“U”、“i”、“V”后使用,使其不与成字声母发生冲突。
本编码所承认的偏旁与键盘上的键帽对应如下:
疒:B(病字旁) 艹 :C(草字头) 丶氵灬 :D(点)
饣:F(饭字旁) 亠 亠+口 :G(高盖头) 衤: H (褐字旁)
钅:J (金字旁) 囗匚冂凵 :K(框字形) 刂 : L (立刀旁)
宀 冖: M(密/幂字头) 纟:N(纽丝旁) 阝: P (陪字旁)
犭:Q(犬字旁) 亻 :R(人字旁) 礻: S (视字旁)
扌:T(提手旁) 攵 夂:W(文字旁/头) 忄 :X (心字旁)
讠:Y(言字旁) 辶 :Z(走字旁) 竹 :Z (竹字头)
C2: 偏旁带异声成字的汉字编码规则。
先取整字声母,再取成字声母,三取【整字】的字型识别码,最后取偏旁代码。
以“储”、“蓝”、“边”、“鸟”四字为例,全码为:“czur(储诸+亻)”、“ljic(蓝监+艹)”、“blvz(边力+辶)”、“nwvd(鸟乌+丶)”。
C3:偏旁与同声成字组成的汉字编码规则。
先取整字声母,再取【整字】字型识别码,三取偏旁代码,最后将该同声成字拆开,取最后一个独立成字成母,不能拆开者则取整字韵母的头一字母。
以“招”、“筐”、“记”、“遛”四字为例, 全码为:“zutk(招+u+ 扌+口)”、“ kizw(筐+i+ 竹+王)” 、“juyi(记+u+ 讠+i)”、“lvzt(遛+v+ 辶+田)”。
C4:若整字在同一字型结构内,由成字和偏旁以及非成字非偏旁组成三结构及三结构以上的汉字,难以分清主次交连与否的复杂混合字型,亦采用模糊方法处理,无视C部以上规则。
依次取整字声母,次取易识别的成字声母和其它成字声母,三取字型识别码,最后取偏旁,超过四码部份舍弃。
以“裹”、“狱”、“辨”、“蓖”、四字为例,全码为:“ggig”、“yquq”、“bxxu”、“bbci”。
D:成字再拆分规则。
d1: 汉字中大批量的存在一种双结构字型,前取意,后取声。在本编码方案中会形成【整字】由成字带与整字同声的成字的编码,即第一码与第三码声母相同组成的汉字。
如“材”、“槽”、“椿”、“楂”、“枞”五字的前三码按编码规则本来都是“cmc”,势必形成大量重码,针对“oxo”码的情况特设编码规则如下:
先取整字声母,再取成字声母,三拆同声字——
a:此同声字不能拆出成字,则取该字的声母和【整字】的字型识别码构成该整字的三、四码。
以“材”字为例,全码为:“cmcu(材木才u)”。
b:此同声字不能拆出成字,但含有偏旁代码,则取该字的声母和偏旁代码构成该整字的三、四码。
以“橄”、“棺”、“槁”三字为例,全码为“gmgw(橄木敢攵)”、“gmgm(棺木官宀”、“gmgg(槁木高亠(+口))”。
c:此同声字只能拆出一个或两个以上,则取同声字与拆出来的成字组成成三、四码。能拆出两个独立成字第四码取后者,拆出两个以上或有多余部份第四码取主体或外围成字代码。
以“椿”、“楂”、“橱”、“短”三字为例,全码为:“cmcr(椿木春日)”、“cmcd(楂木查旦”)、“cmcc”(橱木厨厂) 、“dsdy(短矢豆一)”。
注:“oox(此x下不能包含o。)”码不在此规则之列,如:“就”、“警”二字,全码为:“jjyu”、“jjyi”。
E:韵母。
D1:无独立成字的汉字。
先取声母头一字母为首码(zh ch sh声母中h不取。),再取韵母中的前一、二个字母(不足者取一。),韵母不足三码的字用字型识别码补上,最后取偏旁或字型识别码。
若一字不足四码并不在当前候选框内,可以继续补字型识别码。
以“疑”、“象”、“勿”、“扬”、“寒”、“滴”、“深”七字为例,全编码为:“yiuu”、“ xiai”、 “wuvv”、“yant”、“ hanm”、“ diud”、“send”。
F:重码优化规则(非必学,可略过。)
在以上规则下能方便快捷的打出常用高频字,偶尔会遇上次高频的字有重码。针对这种情况对重码进行第二种编码方案,即用户再遇上这些字时可以用另一种首选方式打出排名靠后的重码。
a:C2: 偏旁带异声成字的汉字编码规则。
先取整字声母,再取成字声母,三取【成字】的字型识别码,最后取偏旁代码。
以 “惭”、“怊”、“惆”三字为例,编码原统一为czux”,第二套编码方案为:“czux”、“czix”、“czvx”。
b: 成字再拆分规则。
1:成字带同声成字
同声字只能拆出两个或两个以上成字,则放弃该同声成字,取分拆出来的两个成字。
以“桔”字为例,第一编码方案为“jmjk”,重码后可打第二套编码方案首码出字:“jmsk(桔木士口)”。
2:成字带异声成字
参见“ D:成字再拆分规则”中的B、C方案。
以“椎”、“槌”、“瞋”三字为例,第一编码方案为“cmzu”,第二编码方案为:“cmzr(椎木隹亻)”、“cmzz(槌木追辶)”、“cmzb(瞋目真八)”。