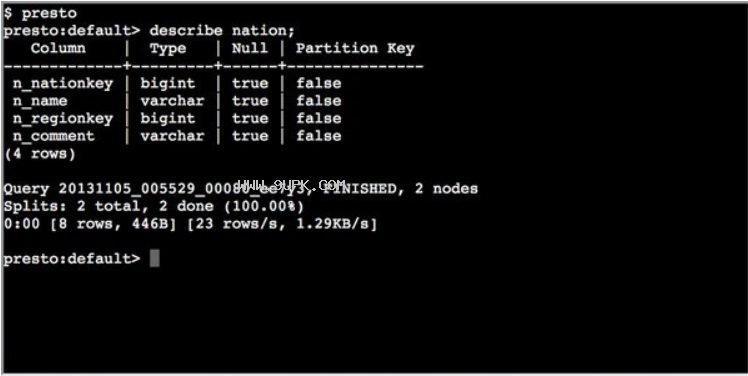
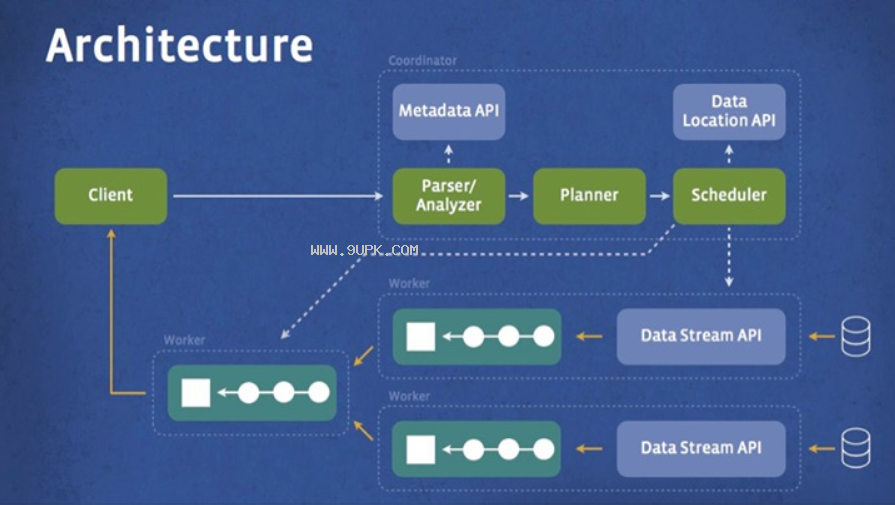
Presto(分布式SQL引擎)是Facebook推出的开源分布式大数据SQL查询引擎软件。第一次构建Presto后,你可以将项目加载到你的IDE中并运行服务器,我们建议使用IntelliJ IDEA,因为Presto是一个标准的Maven项目,你可以使用根pom.xml文件将其导入到你的IDE中。它具有数据存储和计算分析能力,支持多种常用数据源,可以对其进行混合计算分析。同时具有良好的可扩展性,可以扩展开发。
安装方法
预装安装:
Presto是标准的Maven项目。只需从项目根目录运行以下命令:
。/mvnw干净安装
在第一个构建中,Maven将从互联网上下载所有依赖项,并将它们缓存在本地存储库中(~/.m2/repository),这可能需要很多时间。后续构建会更快。
Presto有一套全面的单元测试,可能需要几分钟才能运行。您可以在构建时禁用测试:
。/mvnw干净安装-DskipTests
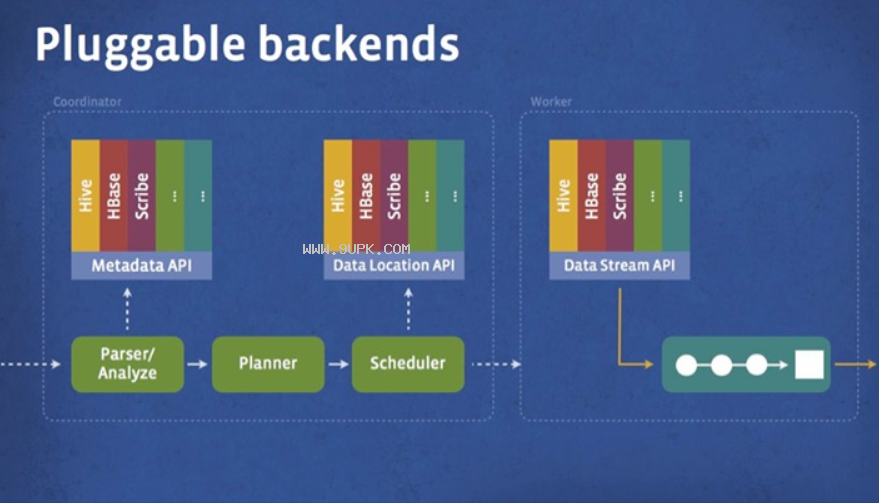
功能特点
1.多数据源和混合计算支持:支持多种常见数据源,可以进行混合计算分析;
2.大数据:完整的内存计算,支持的数据量完全取决于集群内存大小。与SparkSQL不同,sparkSqL可以配置为将溢出的数据保存到磁盘,而Presto是一个完整的内存计算;
3.高性能:低延迟、高并发的内存计算引擎比Hive(不考虑MR、Tez或Spark执行引擎)和Impala效率高得多。根据Facebook和JD.COM的测试报告,至少高出10倍;
4.支持ANSI SQL:与基于HQL(方言)的Hive和SparkSQL不同,Presto是一个标准的SQL。用户可以使用标准的SQL进行数据查询和分析计算;
5.扩展性:SPI扩展点很多,开发者可以写UDF和UDTF。甚至可以实现一个自定义的Connector,下推索引,实现MPP在特殊情况下,借助外部索引功能;
6.PipeLine: Presto是基于PipeLine设计的。在计算大量数据的过程中,最终用户(驱动程序)不需要等到所有数据计算完成后才能看到结果。一旦开始计算,可以立即返回一部分结果,后续的计算结果将在多个页面中返回给最终用户(驱动程序)。






















![SQLyog Community Edition 9.0.0-2 英文版[MySQL数据库管理器]](http://www.9upk.com/statics/images/nopic.gif)
